


Building new weblike things

What’s next for the web? I’ve spent a good chunk of my career trying to answer this question in practice, making the web do things it maybe shouldn’t, like mobile operating systems, and VR.
This is a big question, so I’m tackling it in pieces:
In “Why did the web take over desktop and not mobile?”, I try to understand how the web got to now.
In “The state of the web”, I look at the web in 2021, making the web do apps, and the WebAssembly plot twist.
In “Weird web3 energy”, I explore emerging distributed web efforts.
In “Building new weblike things”, I consider how we might build new open systems with weblike characteristics.
The web is the world’s biggest software platform that isn’t owned. There are other closed networked software platforms but very few open ones. The web mostly stands alone. Why is this? And how might we build more weblike systems?
Forking the web is hazardous
Attempts to build new weblike systems often start by forking the browser. If we fork the browser, we might keep the good stuff, drop the bad stuff, and add new stuff. We get all this for free:
Established network effect
A powerful 2D UI system
A scripting language that can safely hotload untrusted code
An enormous developer ecosystem
By forking an engine like Chromium, or npm-installing Electron you get to the 80% mark very quickly. However, past this point, you start running into “surprises”, usually along one of these axes:
Security and sandboxing problems
Engine complexities when introducing a new native feature
Edge-case issues having to do with the long-tail of web compatibility
An obscure regulatory requirement some country has for things called browsers
This is ignoring other hard stuff, like standardization or cross-browser compatibility.
I’ve done this a few times now, with a mobile operating system, an experimental browser, and a VR browser. It’s always harder than you think.
A browser engine is a complex beast with a particular metabolism, and forking one is like adopting an elephant. If you fork a browser engine in any significant way, you will accidentally turn your project into a browser project and will have to hire a dozen C++ engineers to get anywhere.
The web is an evolved mess
Why is the web so difficult to change? It didn’t start out this way. Building a browser used to be the easiest thing in the world. HTML was originally designed to be a lowest-common-denominator, something you could implement anywhere:
A philosophical rule was that HTML should convey the structure of a hypertext document, but not the details of its presentation. This was the only way to get it to display reasonable on any of a very wide variety of different screens and sizes of paper.
Tim Berner-Lee, 1999, “Weaving the Web”
So that is how we got separation of content and presentation. It was a clever way to exapt existing infrastructure. Presentation wasn’t specified, so you could easily make the web work on anything from a text-only command-line to a graphical user interface, and people did.
But the web didn’t stay that way. HTML gradually evolved to eat every adjacent use-case. The carefully decoupled layers of platform, browser, content, style, behavior all coevolved together, becoming complexly interdependent.


Building a new browser went from being the easiest thing in the world to the hardest thing in the world, because the web is an evolved system, and the API surface of an evolved system is infinite. Dependencies form between things that seem disconnected. Adding or removing anything can cause the whole system to collapse.

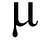
This makes taking “the good parts” of the web impossible. It’s all intertwined and inseparable!
The web is more than the sum of its technologies
A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be made to work. You have to start over, beginning with a simple system.
Gall’s Law
So perhaps we should start over and build a new web from scratch? Alan Kay proposed we do exactly that:
…because the web architecture is so ad hoc, we will instead provide an equivalent simpler functionality that can work within the existing web… This is really easy, and the web could have been easily designed this way, given that HyperCard was already around and thriving to provide a suggestive model when the first web browsers were made. We will follow that ignored path rather than the existing one.
Alan Kay, 2006, “Steps Toward The Reinvention of Programming” NSF proposal
Kay is right. It is easy to do better from first principles. What isn’t easy is rebuilding the network effects of the web from scratch.
The value of the web is not embodied in its technology, so much as in the network of relationships that make up the ecosystem. Ecological networks take a long time to evolve, and can’t just be ported over.
When the web established itself, there was no competition. Today, attempts to reimagine old open networks, like the web or email, have to compete with the network effects of incumbents, and not just the old open networks, but especially the newer closed aggregators.
There is a sense in which rebuilding the web from scratch is like trying to rebuild the Amazon Rainforest from scratch.
Don’t reinvent the web, invent something different
So the web is difficult to evolve, and difficult to replace, but there is a way through this dilemma: build something asymmetric. Podcasts offer a template.
Podcasts share most of the web’s DNA, including URLs and HTTP. They also share many of the web’s best qualities.
Open, distributed, not owned
Evolvable
However, podcasts solve for a radically different job-to-be-done—hands-free listening during a walk or a commute.
Podcasting was so asymmetric it created its own ecological niche, where there was no competition. Even while Facebook’s rise choked out the RSS-blogging ecosystem, podcasting remained untouched. It was built from the same technologies, but existed in an entirely different competitive universe.
This distinct niche allowed podcasts to start small and slowly build new network effects from scratch, developing its own audience, its own content genres, its own advertising ecosystem.
If you want to make a living flower, you don't build it - you grow it from the seed.
Christopher Alexander
The web is an alphabet for creating weblike things
Podcasts share most of the web’s DNA—URLs and HTTP—but swap HTML for RSS. This neatly side-steps the challenge of forking a browser engine. RSS doesn’t have the evolved complexity of HTML, JavaScript, and CSS, so writing a new player is easy.
For the web, [the fundamental] elements were, in decreasing order of importance, universal resource identifiers (URIs), the Hypertext Transfer Protocol (HTTP), and the Hypertext Markup Language (HTML).
Tim Berners-Lee, 1999, “Weaving the Web”
Instead of trying to fork a browser engine, what if we took the same approach as podcasts? There are clean shearing layers between URLs, HTTP, and HTML. What if we viewed the web as an alphabet for building new weblike things?
URLs + HTTP + HTML = web
URLs + HTTP + RSS = Podcasts
URLs + HTTP + JSON = REST APIs
URLs + P2P + HTML = Web3
The design space here feels wide open, and the technological challenge more approachable than forking a browser.

Building more web-like things
The Web does not depend for its existence on any computer technology.
Hakim Bey
It seems likely that much of our lives will be mediated by networked software. Indeed, this is already the case. Much of this mediation happens through platforms owned and controlled by companies, with a few exceptions—web, email, podcasts. It seems valuable to build a few more platforms for networked software that are open, not-owned. Preferably, as many as possible.